
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 반복문
- 대구삼겹살
- 조건문
- 서울맛집
- 브루트 포스
- C#
- 대명동맛집
- BFS
- programmers
- 큐
- 대구맛집
- 압구정데이트
- 프로그래머스
- SQL
- 범어동맛집
- oracle
- 별찍기
- 들안길삼겹살
- 정렬
- 수성구데이트
- 대구데이트
- 오라클
- 앞산카페
- 수성구맛집
- 대구고깃집
- 수성못맛집
- 대구카페
- 수성못삼겹살
- 백준
- 안지랑카페
- Today
- Total
모든 일상
2일차 본문
SQL 실행순수(매우 중요)
from - where - group by - having - select - order by
함수
단일행 함수
-데이터 조작을 위해 사용
-각각의 행에 대해 결과를 반환
-데이터 타입의 변경 가능
-중첩 사용 가능
단일행 함수 구문
select 함수이름(인수1, 인수2, .............)
from dual | 테이블명; (dual 임시 테이블)
문자함수
upper : 대문자
lower : 소문자
initcap : 첫자만 대문자 ( 단어의 첫자가 대문자 )
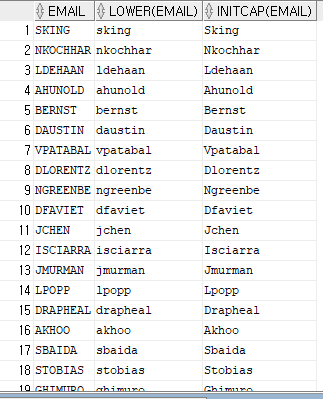
--email의 데이터를 소문자와 첫자만 대문자로 변경
select email, lower(email), initcap(email)
from emp
--email이 sking인 사람을 검색
1)
select *
from emp
where upper(email) = upper('sking');
2)
select *
from emp
where email = upper('sking');
3)
select *
from emp
where upper(email) = ('sking');
=> 결과는 모두 동일하다. 하지만 2번이 가장 효과적이다.
=> 검색 조건의 컬럼에 인덱스가 있는 경우 함수를 사용하면 변형이 되므로 인덱스를 사용하지않고 푸스캔하여 속도가 떨어진다.
substr(컬럼명, 시작위치, (문자개수)-생략 가능) - 문자의 일부분을 가져온다.
-시작위치 >0 : 인덱스 왼쪽부터 1로 시작하고, 반대로 시작위치가 < 0 : 인덱스 번호가 오른쪽부터 1로 시작한다.
--email의 앞에서부터 1~3문자와 끝에 두자리를 가져온다.
select email, substr(email, 1, 3), substr(email, -2)
from emp;

instr(컬럼명, '찾고자 하는 문자 또는 문자열')
instr(컬럼명, '찾고자 하는 문자 또는 문자열', [시작위치, 몇번째것] ) -> 찾는 문자의 시작위치
--email안에서 대문자 S가 위치하는 위치를 검색 ( S가 없으면 0으로 반환, S가 여러개있으면 첫번째 위치가 반환)
select email, instr(email, 'S')
from emp;

--email에 s가 여러개 있는 경우 첫번째 s이후 두번째 s가 몇번째 위치에 있는지 검색
select email, instr(email, 'S', 1, 2)
from emp;

-- job_id 컬럼에서 '_' 앞 뒤 문자열 검색
select job_id, substr(job_id, 1, instr(job_id,'_')-1) as 앞, substr(job_id,instr(job_id,'_')+1) as 뒤
from emp;

length(컬럼명)
- 해당 컬럼의 문자의 길이
- 영어, 숫자, 특수문자, 공백, 한글 => 한글자로 인식
--email의 길이를 알려주고, "안녕하세요."의 문자열의 길이
select email, length(email), length('안녕하세요.')
from emp;

lpad(컬럼명, 전체사이즈, '채울문자') - 왼쪽으로 채우는 문자 <-> rpad 오른쪽에 채우는문자
--총 15의 길이속에 왼쪽부터 '*'을 채우고 email을 입력한다..
select email, lpad( email, 15, '*')
from emp;

--email를 앞자리 3자만 가져오고 나머지는 '*' 로 처리하여 검색
select email, substr(email,1,3), rpad(substr(email,1,3),length(email),'*')
from emp;

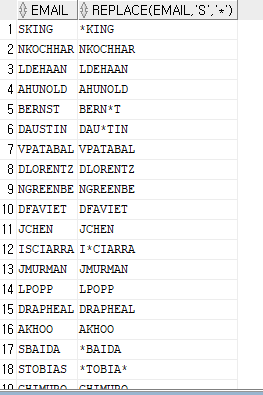
replce(컬럼명, '찾는문자열', '바꿀문자')
trim(컬럼명)
- 컬럼의 앞뒤 공백을 잘라준다.
- 문자 중간의 공백은 유지된다.
숫자함수
trunc( 컬럼명, 자릿수 )
- 버림
round( 컬럼명, 자릿수 )
- 반올림
- 자릿수 (' . '이 기준으로 0번이고 '.'을 기준으로 오른쪽으로 1 2 3 순서이고 왼쪽으로 -1 -2 -3으로 진행이 된다.
자리수가 0이면 정수만 표시)
--커미션퍼센트를 소수점 이후 첫번째자리까지 반올림 내림을 표현
select commission_pct, round(commission_pct,1), trunc(commission_pct,1)
from emp
where commission_pct is not null;

--실수점을 기준으로 왼쪽부터 -1, -2, -3 순서로 -3위치에서 반올림한다.
select salary, round(salary, -3)
from emp;

날짜 함수
-날짜 타입의 자료는 연산이 가능하다.
-> 날짜 - 날짜, 날짜 + 날짜
- 날짜 타입 : 세기, 년, 월, 일, 시, 분, 초 -7가지 정보
- 날짜 + 숫자 -> 일자에 연산이 된다.
- +, - 연산만 가능 ( *, / 연산은 불가능)
--입사일에 +10을 하는데 일자 정보에 +가 적용되는 결과
select hire_date, hire_date +10
from emp;

--날짜 - 날짜는 모두 일자로 변경해서 연산을 한다. 그래서 알아보기 어렵다.
select sysdate - hire_date
from emp;

add_months( 날짜컬럼, 개월수(+, - 가능하다.) )
--날짜 정보에서 월 정보에 3을 더한 결과
select hire_date, add_months(hire_date, 3)
from emp;

--날짜 정보에서 월 정보에 3을 뺀 결과
select hire_date, add_months(hire_date, -3)
from emp;

months_between(최근 날짜, 오래된 날짜)
- 두 날짜 사이의 개월수
--사원의 근월수 계산 소숫점 뒷자리는 버림
select last_name, hire_date, trunc(months_between(sysdate, hire_date),0) as 근속월수
from emp;

extract( year from 날짜컬럼 ) ->year, month, day, hour, 등 사용 가능
- 날짜 칼럼에 일부 정보만 추출
--2004년에 입사한 사람만 검색
select last_name, hire_date
from emp
where extract ( year from hire_date ) ='2004';

last_day(날짜컬럼)
- 마지막 날
--해당 날짜의 달에 마지막 날
select hire_date, last_day(hire_date)
from emp;

next_day(날짜컬럼, 구분 )
- 구분 : 요일
- 요일 : 숫자 : 일 월 화 수 목 금 토 -> 1 2 3 4 5 6 7
- 날짜컬럼 이후 요일의 날짜
--입사일 이후의 7 = 토요일 의 날짜를 표시
select hire_date, next_day(hire_date, 7)
from emp;

--round, trunc 사용가능
select hire_date, round(hire_date, 'month')
from emp;

일반 함수
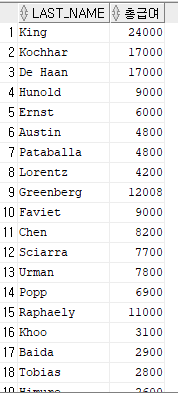
nvl( 컬럼명, null 일 경우 대신 반환할 값 ) - 중요함
총 급여 = salary + (salary + nvl(commission_pct,0))
--커미션퍼센트 데이터가 null인 데이터들을 0으로 반환하여 계산 한다.
select last_name, salary + (salary * nvl (commission_pct,0)) as 총급여
from emp
nvl2( 컬럼명, null이 아닐 경우 , null일 경우 )
select last_name, nvl2(commission_pct, '수당 받음', '수당 안받음')
from emp;

case 문
- 쿼리문 안의 조건문
--월급의 2배 보너스를 지급하고자 한다. 모두 동일한 보너스를 받는다.
select last_name, salary, salary * 2 as bonus
from emp;

--부서별로 보너스를 다르게 지급하려고 한다. 20- 2배, 30-3배, 40-4배, 나머지는 월급의 1배를 지급하려고 한다.
select last_name, salary, department_id,
case department_id when 20 then salary*2
when 30 then salary*3
when 40 then salary*4
else
salary * 1
end as bonus
from emp;

case문과 decode()함수는 서로 변경이 가능하다.
select last_name, salary, department_id,
decode( department_id ,
20 , salary*2,
30 ,salary*3 ,
40 ,salary*4,
salary * 1)
as bonus
from emp; => 소스 역시 위의 case문 소스와 같은 결과를 실행한다.
형전환 함수
- to_date()
- to_number()
- to_char()
to_char()
- 숫자 또는 날짜를 표시형식으로 바꿔서 출력할 경우
날짜 ->문자
--현재 날짜와 시간을 표시
select sysdate, to_char(sysdate, 'yy-mm-dd hh : mi : ss') from dual

select sysdate, to_char(sysdate, 'yy-mm-dd am hh : mi : ss') from dual

select sysdate, to_char(sysdate, 'yy-mm-dd dy hh : mi : ss') from dual

select sysdate, to_char(sysdate, 'yy-mon-dd hh : mi : ss') from dual

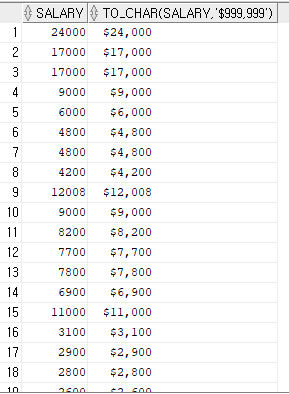
숫자 -> 문자
-천단위, 콤마, 화폐단위........
select salary, to_char(salary, '$999,999') from emp;
select salary, to_char(salary, '$009,999') from emp;

select salary, to_char(salary, 'l999,999') from emp;

